|
|
|
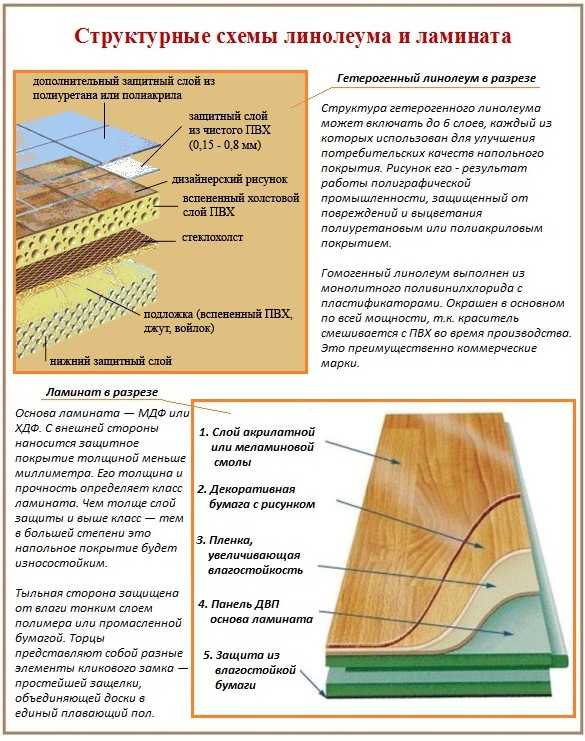
Как считается погонный метр линолеума
Как рассчитать погонный метр линолеума через квадратный Ремонт квартиры – одно из самых непростых и затратных мероприятий для бюджета любого человека. Приступая к нему, хозяин должен заранее распланировать все работы, рассчитать количество всего, что может потребоваться, и перевести это количество в стоимость. Первое, о чем он задумывается в этом случае, сколько всевозможных отделочных материалов (обоев, краски и т.д.) ему необходимо приобрести. Для отделки пола в квартире в настоящее время обычно используется линолеум – он намного практичнее традиционной в прошлом краски, т.к. его укладка не связана с большими временными затратами, да и по долговечности показатели этого материала куда лучше. Стоимость его достаточно высока, поэтому при выборе линолеума в магазине возникает потребность как можно точнее посчитать, сколько его нужно приобрести, чтобы не купить лишнего, но в то же время не допустить нехватки.
Большинство взрослых людей (да и школьников) хорошо знают, что такое линейный метр и квадратный метр. В обыденной жизни мы встречаемся с ними достаточно часто: первые помогают нам рассчитать длину, а вторые – площадь чего-либо, в том числе и помещений. Но, как правило, рулонные материалы продаются не в квадратных, а в погонных. Что собой представляет метр погонный, чем он отличается от квадратного, и как они связаны между собой, знают не все. Между тем при проведении ремонтных работ подобное знание бывает необходимо. Давайте попробуем разобраться, что же означает этот термин. Погонный метр – что это такое? Строго говоря, понятие «погонный метр» применяется в основном в торговле рулонными товарами (тканью, пленкой, ковролином, линолеумом и т.д.). В нем учитывается только линейная длина измеряемого материала, ширина в данном случае в расчет не принимается, так что вполне можно сказать, что в этом смысле погонный метр ничем не отличается от линейного. Но покупателю при покупке рулона чего-либо учитывать его ширину, естественно, совершенно необходимо – ведь от этого напрямую зависит, какое количество того же линолеума нужно приобрести, и какова будет его стоимость в конечном счете. А теперь о том, как рассчитать число погонных метров. Способы расчета Первый способ заключается в том, чтобы попытаться перевести погонные метры в квадратные (либо наоборот: перевести последние в первые). Предположим, имеется 5 пог. м. линолеума шириной 2,5 м. Стало быть, площадь данного куска равна 5 × 2,5, т.е. 12,5 м2, и если площадь ремонтируемого помещения – 25 м2, то для покрытия пола в нем необходимо два таких куска.
В тех случаях, когда необходимо сделать обратный пересчет, превращая «квадраты» в погонный метраж, нужно площадь материала поделить на его ширину. Допустим, имеется в наличии кусок линолеума площадью 12,5 м2, и шириной 2,5 м. В таком случае перевести число кв. м. в нем в погонные не представляет труда: простейшая арифметическая операция показывает, что оно будет равно 5. При этом следует учесть, что присутствие ширины материала в данных расчетах совершенно необходимо: без него получить искомые данные никак нельзя. Но для определения данного показателя при покупке линолеума есть и «непереводной» метод, пользоваться которым гораздо удобнее. Вот как это выглядит в действии. Проще всего, если ширина данного материала полностью совпадает с шириной комнаты, в которой необходимо застелить пол: тогда число пог. м. станет равняться длине помещения, да и результат работы без швов выглядеть будет гораздо красивее. Когда же эти показатели различны (а именно так чаще всего и случается), линолеум приходится стыковать, и в таких случаях рассчитать искомую величину более сложно. Приведем пример.
Необходимо застелить линолеумом пол в комнате, длина которой – 5 м, а ширина 3 м. Длина кусков не зависит от ширины рулона, и в любом случае должна равняться длине комнаты, т.е. 5 м. Показатель ширины комнаты в данном случае удобнее разделить пополам – для этого потребуется рулон шириной 1.5 м. Состыковав вместе два полотна, как раз и получим искомую величину. Чтобы посчитать, сколько нам необходимо погонных метров, умножаем число полотен (кусков) на их длину: 2 × 6 = 12. Значит, для выполнения данной операции понадобится 12 погонных метров покрытия шириной 1,5 м. Если же ширина комнаты при той же длине составляет 4,5 м, то возможны два варианта: придется использовать либо три куска линолеума шириной 1,5 м (1,5 + 1,5 + 1,5), либо два куска: один двухметровой ширины и один – 2,5 м. В первом случае число погонных метров будет равняться 18 (6 × 3), во втором – 12 (6 × 2).
То есть и в том, и в другом случае нужно вначале определить, какой ширины линолеум будет использоваться, и сколько полос потребуется, чтобы полностью покрыть ширину помещения. Чтобы рассчитать, сколько денег придется потратить на покупку, нужно умножить стоимость 1 м такой полосы на их общее количество Экономьте, но не жадничайте Размеры, естественно, подбираются, исходя из необходимости исключить появление при этом неиспользованных обрезков, либо свести их объем к минимуму. Однако с другой стороны, следует заметить, что, рассчитывая количество любых необходимых в ремонте материалов, не стоит делать этого «впритык»: такой способ может сильно подвести мастера, поэтому всегда необходимо иметь в виду так называемые припуски. Самые лучшие посты Насколько велика Земля? - Радиус, диаметр и окружность с пояснениями Земля, третья планета от Солнца, является пятой по величине планетой Солнечной системы; только газовые гиганты Юпитер, Сатурн, Уран и Нептун больше. Земля - самая большая из планет земной группы внутренней солнечной системы, больше Меркурия, Венеры и Марса. Но насколько велика Земля? Радиус, диаметр и окружность Радиус Земли на экваторе составляет 3963 мили (6378 километров), согласно данным Центра космических полетов имени Годдарда НАСА.Однако Земля не совсем сфера. Вращение планеты заставляет ее выпирать на экваторе. Полярный радиус Земли составляет 3950 миль (6356 км), разница в 13 миль (22 км).
Используя эти измерения, экваториальная окружность Земли составляет около 24 901 миль (40 075 км). Однако от полюса до полюса - меридиональной окружности - Земля составляет всего 24 860 миль (40 008 км) вокруг. Эта форма, вызванная уплощением полюсов, называется сплюснутым сфероидом. Связанный: Какова скорость Земли вокруг Солнца? Плотность, масса и объем Плотность Земли равна 5.По данным НАСА, 513 граммов на кубический сантиметр. Земля - самая плотная планета в Солнечной системе из-за ее металлического ядра и каменистой мантии. Юпитер, который на 318 массивнее Земли, менее плотный, потому что он состоит из газов, таких как водород. Масса Земли составляет 6,6 секстиллиона тонны (5,9722 x 10 24 килограмма). Его объем составляет около 260 миллиардов кубических миль (1 триллион кубических километров). Общая площадь поверхности Земли составляет около 197 миллионов квадратных миль (510 миллионов квадратных километров).Около 71 процента покрыто водой и 29 процентов - сушей. Самая высокая и самая низкая точки Гора Эверест - самое высокое место на Земле над уровнем моря, на высоте 29 028 футов (8848 метров), но это не самая высокая точка на Земле, то есть место, наиболее удаленное от центра Земля. По данным Национального управления океанических и атмосферных исследований (NOAA), эта награда принадлежит горе Чимаборасо в Андах в Эквадоре. Хотя Чимаборасо примерно на 10 000 футов короче (относительно уровня моря), чем Эверест, эта гора находится примерно на 6 800 футов (2073 м) дальше в космос из-за экваториальной выпуклости. По данным NOAA, самая низкая точка на Земле - это Глубина Челленджера в Марианской впадине в западной части Тихого океана. Его высота составляет около 36 200 футов (11 034 метра) ниже уровня моря. . 5 алгоритмов кластеризации, которые необходимо знать ученым | Джордж Сейф Кластеризация - это метод машинного обучения, который включает в себя группировку точек данных. Учитывая набор точек данных, мы можем использовать алгоритм кластеризации для классификации каждой точки данных в определенную группу. Теоретически точки данных, которые находятся в одной группе, должны иметь похожие свойства и / или функции, в то время как точки данных в разных группах должны иметь очень разные свойства и / или функции. Кластеризация - это метод обучения без учителя и распространенный метод статистического анализа данных, используемый во многих областях. В Data Science мы можем использовать кластерный анализ, чтобы получить ценную информацию из наших данных, наблюдая, в какие группы попадают точки данных, когда мы применяем алгоритм кластеризации. Сегодня мы рассмотрим 5 популярных алгоритмов кластеризации, которые необходимо знать специалистам по данным, а также их плюсы и минусы! Кластеризация K-средних K-средних, вероятно, самый известный алгоритм кластеризации. Его преподают на многих вводных курсах по науке о данных и машинному обучению. Это легко понять и реализовать в коде! Посмотрите рисунок ниже для иллюстрации. Кластеризация K-средних - Для начала мы сначала выбираем несколько классов / групп для использования и случайным образом инициализируем их соответствующие центральные точки. Чтобы определить количество используемых классов, полезно быстро взглянуть на данные и попытаться выделить какие-либо отдельные группы. Центральные точки - это векторы той же длины, что и каждый вектор точек данных, и обозначены буквами «X» на рисунке выше.
- Каждая точка данных классифицируется путем вычисления расстояния между этой точкой и центром каждой группы, а затем классификации точки в группе, центр которой находится ближе всего к ней.
- На основе этих классифицированных точек мы повторно вычисляем центр группы, взяв среднее значение всех векторов в группе.
- Повторите эти шаги для заданного количества итераций или до тех пор, пока центры групп не будут сильно меняться между итерациями. Вы также можете выбрать случайную инициализацию групповых центров несколько раз, а затем выбрать прогон, который, похоже, обеспечил наилучшие результаты.
K-Means имеет то преимущество, что он довольно быстр, поскольку все, что мы на самом деле делаем, это вычисляем расстояния между точками и центрами групп; очень мало вычислений! Таким образом, он имеет линейную сложность O ( n ). С другой стороны, у K-Means есть несколько недостатков. Во-первых, вы должны выбрать количество групп / классов. Это не всегда тривиально, и в идеале с алгоритмом кластеризации мы хотели бы, чтобы он выяснял это за нас, потому что его цель - получить некоторое представление о данных. K-средство также начинается со случайного выбора центров кластеров и, следовательно, может давать разные результаты кластеризации при разных прогонах алгоритма. Таким образом, результаты могут быть неповторимыми и непротиворечивыми.Другие кластерные методы более последовательны. K-Medians - это еще один алгоритм кластеризации, связанный с K-средними, за исключением того, что вместо пересчета центральных точек группы с использованием среднего мы используем медианный вектор группы. Этот метод менее чувствителен к выбросам (из-за использования медианы), но намного медленнее для больших наборов данных, так как сортировка требуется на каждой итерации при вычислении медианного вектора. Кластеризация со средним сдвигом Кластеризация со средним сдвигом - это алгоритм на основе скользящего окна, который пытается найти плотные области точек данных.Это алгоритм на основе центроидов, означающий, что цель состоит в том, чтобы найти центральные точки каждой группы / класса, который работает путем обновления кандидатов на центральные точки, чтобы они были средними точками в скользящем окне. Эти окна кандидатов затем фильтруются на этапе постобработки, чтобы исключить почти дубликаты, образуя окончательный набор центральных точек и их соответствующих групп. Посмотрите рисунок ниже для иллюстрации. Кластеризация среднего сдвига для одного скользящего окна - Чтобы объяснить средний сдвиг, мы рассмотрим набор точек в двумерном пространстве, как на иллюстрации выше.Мы начинаем с круглого скользящего окна с центром в точке C (выбранной случайным образом) и с радиусом r в качестве ядра. Среднее смещение - это алгоритм подъема в гору, который включает итеративное смещение этого ядра в область с более высокой плотностью на каждом шаге до сходимости.
- На каждой итерации скользящее окно смещается в сторону областей с более высокой плотностью за счет смещения центральной точки на среднее значение точек в пределах окна (отсюда и название). Плотность внутри скользящего окна пропорциональна количеству точек внутри него.Естественно, при переходе к среднему значению точек в окне он будет постепенно перемещаться в области с более высокой плотностью точек.
- Мы продолжаем сдвигать скользящее окно в соответствии со средним значением, пока не будет направления, в котором сдвиг может вместить больше точек внутри ядра. Посмотрите на рисунок выше; мы продолжаем перемещать круг до тех пор, пока не перестанем увеличивать плотность (то есть количество точек в окне).
- Этот процесс шагов 1-3 выполняется с множеством скользящих окон, пока все точки не окажутся внутри окна.Когда несколько скользящих окон перекрываются, окно, содержащее наибольшее количество точек, сохраняется. Затем точки данных группируются в соответствии со скользящим окном, в котором они находятся.
Иллюстрация всего процесса от начала до конца со всеми скользящими окнами показана ниже. Каждая черная точка представляет собой центр тяжести скользящего окна, а каждая серая точка - это точка данных. Весь процесс кластеризации среднего сдвига В отличие от кластеризации K-средних, нет необходимости выбирать количество кластеров, поскольку средний сдвиг автоматически обнаруживает это.Это огромное преимущество. Тот факт, что центры кластера сходятся к точкам максимальной плотности, также весьма желателен, поскольку это довольно интуитивно понятно для понимания и хорошо подходит для естественного управления данными. Недостатком является то, что выбор размера / радиуса окна «r» может быть нетривиальным. Пространственная кластеризация приложений с шумом на основе плотности (DBSCAN) DBSCAN - это кластерный алгоритм на основе плотности, аналогичный среднему сдвигу, но с несколькими заметными преимуществами.Посмотрите еще одну красивую картинку ниже, и приступим! DBSCAN Smiley Face Clustering - DBSCAN начинается с произвольной начальной точки данных, которая не была посещена. Окрестность этой точки извлекается с использованием расстояния epsilon ε (все точки, находящиеся в пределах расстояния ε, являются точками окрестности).
- Если в этой окрестности имеется достаточное количество точек (согласно minPoints), то запускается процесс кластеризации, и текущая точка данных становится первой точкой в новом кластере.В противном случае точка будет помечена как шум (позже эта зашумленная точка может стать частью кластера). В обоих случаях эта точка помечается как «посещенная».
- Для этой первой точки в новом кластере точки в пределах ее окрестности расстояния ε также становятся частью того же кластера. Эта процедура приведения всех точек в окрестности ε к одному кластеру затем повторяется для всех новых точек, которые были только что добавлены в группу кластеров.
- Этот процесс шагов 2 и 3 повторяется до тех пор, пока не будут определены все точки в кластере i.e все точки в пределах ε окрестности кластера были посещены и помечены.
- Когда мы закончим с текущим кластером, новая непосещенная точка извлекается и обрабатывается, что приводит к обнаружению следующего кластера или шума. Этот процесс повторяется до тех пор, пока все точки не будут отмечены как посещенные. Поскольку в конце этого процесса все точки были посещены, каждая точка будет отмечена либо как принадлежащая кластеру, либо как шумовая.
DBSCAN обладает некоторыми большими преимуществами перед другими алгоритмами кластеризации.Во-первых, он вообще не требует определенного количества кластеров. Он также определяет выбросы как шумы, в отличие от среднего сдвига, который просто отбрасывает их в кластер, даже если точки данных сильно отличаются. Кроме того, он может довольно хорошо находить кластеры произвольного размера и произвольной формы. Главный недостаток DBSCAN заключается в том, что он не работает так же хорошо, как другие, когда кластеры имеют разную плотность. Это связано с тем, что установка порогового значения расстояния ε и minPoints для идентификации точек соседства будет варьироваться от кластера к кластеру при изменении плотности.Этот недостаток также возникает с данными очень большого размера, поскольку снова становится сложно оценить пороговое значение расстояния ε. Кластеризация ожидания – максимизации (EM) с использованием моделей смешения гауссов (GMM) Одним из основных недостатков K-средних является наивное использование среднего значения для центра кластера. Мы можем понять, почему это не лучший способ решения задач, посмотрев на изображение ниже. С левой стороны человеческому глазу совершенно очевидно, что есть два круглых кластера с разным радиусом 'с одним и тем же средним значением.K-средние не справятся с этим, потому что средние значения кластеров очень близки друг к другу. K-среднее также не работает в тех случаях, когда кластеры не являются круговыми, опять же в результате использования среднего в качестве центра кластера. Два случая отказа для К-средних. Гауссовские модели смеси (GMM) дают нам больше гибкости, чем К-средние. В случае GMM мы предполагаем, что точки данных распределены по Гауссу; это менее ограничительное предположение, чем утверждение, что они являются круговыми с использованием среднего. Таким образом, у нас есть два параметра для описания формы кластеров: среднее значение и стандартное отклонение! Если взять пример в двух измерениях, это означает, что кластеры могут принимать любую форму эллипса (поскольку у нас есть стандартное отклонение как по осям x, так и по y).Таким образом, каждое гауссовское распределение относится к одному кластеру. Чтобы найти параметры гауссианы для каждого кластера (например, среднее значение и стандартное отклонение), мы будем использовать алгоритм оптимизации, называемый ожиданием – максимизацией (EM). Взгляните на рисунок ниже, как иллюстрацию подгонки гауссиан к кластерам. Затем мы можем приступить к процессу кластеризации ожидания – максимизации с использованием GMM. EM-кластеризация с использованием GMM - Мы начинаем с выбора количества кластеров (как это делает K-Means) и случайной инициализации параметров гауссова распределения для каждого кластера.Можно попытаться дать хорошую оценку начальных параметров, также быстро взглянув на данные. Хотя обратите внимание, как видно на графике выше, это не обязательно на 100%, поскольку гауссианы начинают наши как очень плохие, но быстро оптимизируются.
- Учитывая эти гауссовские распределения для каждого кластера, вычислите вероятность того, что каждая точка данных принадлежит определенному кластеру. Чем ближе точка к центру Гаусса, тем больше вероятность, что она принадлежит этому кластеру. Это должно иметь интуитивный смысл, поскольку с распределением Гаусса мы предполагаем, что большая часть данных находится ближе к центру кластера.
- На основе этих вероятностей мы вычисляем новый набор параметров для гауссовских распределений, чтобы максимизировать вероятности точек данных в кластерах. Мы вычисляем эти новые параметры, используя взвешенную сумму позиций точек данных, где веса - это вероятности принадлежности точки данных к этому конкретному кластеру. Чтобы объяснить это наглядно, мы можем взглянуть на рисунок выше, в частности на желтый кластер в качестве примера. Распределение начинается случайным образом на первой итерации, но мы видим, что большинство желтых точек находятся справа от этого распределения.Когда мы вычисляем сумму, взвешенную по вероятностям, даже несмотря на то, что рядом с центром есть некоторые точки, большинство из них находятся справа. Таким образом, естественно, что среднее значение распределения смещается ближе к этому набору точек. Мы также можем видеть, что большинство точек расположены «сверху-справа-снизу-слева». Поэтому стандартное отклонение изменяется, чтобы создать эллипс, который больше соответствует этим точкам, чтобы максимизировать сумму, взвешенную по вероятностям.
- Шаги 2 и 3 повторяются итеративно до сходимости, когда распределения не сильно меняются от итерации к итерации.
Использование GMM дает два ключевых преимущества. Во-первых, GMM намного больше гибких с точки зрения кластерной ковариации , чем K-средних; из-за параметра стандартного отклонения кластеры могут принимать любую форму эллипса, а не ограничиваться кругами. K-средние фактически являются частным случаем GMM, в котором ковариация каждого кластера по всем измерениям приближается к нулю. Во-вторых, поскольку GMM использует вероятности, они могут иметь несколько кластеров на точку данных. Итак, если точка данных находится в середине двух перекрывающихся кластеров, мы можем просто определить ее класс, сказав, что она принадлежит X-процентов к классу 1 и Y-процентам к классу 2.То есть GMM поддерживают смешанное членство . Агломеративная иерархическая кластеризация Алгоритмы иерархической кластеризации делятся на 2 категории: нисходящие и восходящие. Восходящие алгоритмы обрабатывают каждую точку данных как единый кластер вначале, а затем последовательно объединяют (или агломерат ) пары кластеров, пока все кластеры не будут объединены в единый кластер, содержащий все точки данных. Таким образом, восходящая иерархическая кластеризация называется иерархической агломеративной кластеризацией или HAC .Эта иерархия кластеров представлена в виде дерева (или дендрограммы). Корень дерева - это уникальный кластер, который собирает все образцы, а листья являются кластерами только с одним образцом. Перед тем, как перейти к шагам алгоритма, посмотрите рисунок ниже. Агломеративная иерархическая кластеризация - Мы начинаем с обработки каждой точки данных как одного кластера, т.е. если в нашем наборе данных есть X точек данных, то у нас есть X кластеров. Затем мы выбираем метрику расстояния, которая измеряет расстояние между двумя кластерами.В качестве примера мы будем использовать среднее значение связи , которое определяет расстояние между двумя кластерами как среднее расстояние между точками данных в первом кластере и точками данных во втором кластере.
- На каждой итерации мы объединяем два кластера в один. Два кластера, которые необходимо объединить, выбираются как кластеры с наименьшей средней связью. То есть, согласно выбранной нами метрике расстояния, эти два кластера имеют наименьшее расстояние между собой и, следовательно, наиболее похожи и должны быть объединены.
- Шаг 2 повторяется до тех пор, пока мы не достигнем корня дерева, т.е. у нас будет только один кластер, содержащий все точки данных. Таким образом, мы можем выбрать, сколько кластеров мы хотим в конце, просто выбрав, когда прекратить объединение кластеров, то есть когда мы перестанем строить дерево!
Иерархическая кластеризация не требует от нас указания количества кластеров, и мы даже можем выбрать, какое количество кластеров выглядит лучше всего, поскольку мы строим дерево. Кроме того, алгоритм нечувствителен к выбору метрики расстояния; все они работают одинаково хорошо, тогда как с другими алгоритмами кластеризации выбор метрики расстояния имеет решающее значение.Особенно хороший вариант использования методов иерархической кластеризации - это когда базовые данные имеют иерархическую структуру, и вы хотите восстановить иерархию; другие алгоритмы кластеризации не могут этого сделать. Эти преимущества иерархической кластеризации достигаются за счет более низкой эффективности, поскольку она имеет временную сложность O (n³) , в отличие от линейной сложности K-средних и GMM. . Каким был бы мир, если бы весь лед растаял ![]() Если мы будем продолжать сжигать ископаемое топливо бесконечно долго, глобальное потепление в конечном итоге растопит весь лед на полюсах и на вершинах гор, подняв уровень моря на 216 футов. Узнайте, как будут выглядеть новые береговые линии мира. Эта история появляется в Сентябрь 2013 г. Журнал National Geographic . Карты здесь показывают мир таким, какой он есть сейчас, с единственным отличием: весь лед на суше растаял и сошел в море, подняв его на 216 футов и создав новые береговые линии для наших континентов и внутренних морей. На Земле более пяти миллионов кубических миль льда, и некоторые ученые говорят, что потребуется более 5000 лет, чтобы все это растопить. Если мы продолжим добавлять углерод в атмосферу, мы, скорее всего, создадим планету, свободную ото льда, со средней температурой около 80 градусов по Фаренгейту вместо нынешних 58. . IELTS Практический тест чтения 77 с ответами ЧТЕНИЕ 3 Вам следует потратить около 20 минут на вопросов 28-40 , которые основаны на отрывке для чтения 3 ниже. ДА БУДЕТ СВЕТ? А «Лампы накаливания освещали ХХ век; 21-м будет Jit by LED lamp ». Так заявил комитет по Нобелевской премии по присуждению премии по физике 2014 года изобретателям светодиодов (LED). Во всем мире светодиодные системы заменяют большинство видов обычного освещения, поскольку они потребляют примерно половину электроэнергии, и Министерство энергетики США ожидает, что к 2030 году на светодиоды будут приходиться 74% продаж освещения в США. Однако при меньших эксплуатационных расходах светодиоды можно оставить включенными дольше или установить в местах, которые ранее не горели. Исторически сложилось так, что при улучшении технологии освещения происходило гораздо больше наружного освещения. Кроме того, многие светодиоды ярче, чем другие источники света, и излучают свет с синей длиной волны, которую животные ошибочно принимают за рассвет. По данным Американской медицинской ассоциации, наблюдается заметный рост ожирения, диабета, рака и сердечно-сосудистых заболеваний среди людей, таких как сменные рабочие, которые подвергаются воздействию слишком большого количества искусственного света любого рода. Скорее всего, более распространенные светодиоды будут способствовать дальнейшему росту. B В некоторых городах коричневая дымка промышленных загрязнений мешает наслаждаться ночным небом; в других случаях желтая дымка от освещения имеет такой же эффект, и считается, что почти 70% людей больше не видят Млечный Путь. Когда небольшое землетрясение привело к отключению электростанций в Лос-Анджелесе несколько лет назад, директор обсерватории Гриффита был засыпан телефонными звонками местных жителей, которые сообщили о необычном явлении, которое, по их мнению, было вызвано землетрясением - ярко освещенное ночное небо, на котором было видно около 7000 звезд. Фактически, это была обычная звездная ночь, которую редко можно увидеть в Лос-Анджелесе из-за светового загрязнения! Несомненно, световое загрязнение затрудняет профессиональную астрономию, но оно также ставит под угрозу вековую связь людей со звездами.Вполне возможно, что дети, которые не переживают по-настоящему звездную ночь, не могут рассуждать о Вселенной и не могут узнать о ночных существах. К Чрезмерное освещение влияет на ночной мир. Около 30% позвоночных и более 60% беспозвоночных ведут ночной образ жизни; многие из оставшихся - сумеречные - наиболее активны на рассвете и в сумерках. Ночное освещение, в сотни тысяч раз превышающее его естественный уровень, резко сократило количество насекомых, птиц, летучих мышей, ящериц, лягушек, черепах и рыб, причем даже дойные коровы производят меньше молока в ярко освещенных сараях. Ночное освещение действует как пылесос на насекомых, особенно бабочек, вытягивая их с расстояния до 122 метров. Поскольку насекомые играют важную роль в опылении и обеспечении птиц пищей, их уничтожение является серьезной проблемой. Использование натриевых ламп низкого давления или ламп с УФ-фильтром снизило бы смертность насекомых, но альтернативный источник света не помогает амфибиям: туман, освещенный любым ночным светом, изменяет поведение при кормлении и спаривании, делая их легкой добычей. Кроме того, птицы и насекомые используют солнце, луну и звезды для навигации. По оценкам, около 500 миллионов перелетных птиц ежегодно погибают в результате столкновений с ярко освещенными сооружениями, такими как небоскребы или радиовышки. В Торонто, Канада, Программа осведомленности о смертельном свете информирует владельцев зданий о сокращении таких смертей путем затемнения их зданий в разгар сезона миграции. Тем не менее, более 1500 птиц могут быть убиты за одну ночь, если этого не произойдет. Немигрирующие птицы также страдают от светового загрязнения - сон затруднен, а пробуждение происходит только тогда, когда солнце перекрывает искусственное освещение, в результате чего птицы опаздывают, чтобы поймать насекомых. Кожаные черепахи, которые жили на Земле более 150 миллионов лет, теперь находятся под угрозой исчезновения, поскольку их птенцы должны следовать за светом, отраженным от луны и звезд, и переходить от своих песчаных гнезд к морю. Вместо этого они следуют за уличными фонарями или гостиничными фонарями, что приводит к смерти от обезвоживания, хищничества или несчастных случаев, поскольку они выходят на дорогу в противоположном от моря направлении. D В настоящее время восемь процентов всей энергии, вырабатываемой в США, направляется на наружное освещение, и многие свидетельства показывают, что освещение и потребление энергии растут примерно на четыре процента в год, опережая рост населения. В некоторых новых индустриальных странах использование освещения увеличивается на 20%. К сожалению, по мере урбанизации развивающегося мира он также ярко светится, вместо того чтобы делать выбор в пользу устойчивости. E Есть несколько организаций, занимающихся восстановлением ночного неба: одна из них - Международная ассоциация темного неба (IDA), базирующаяся в Аризоне, США.IDA обращает внимание на опасность светового загрязнения и работает с производителями, проектировщиками, законодателями и гражданами, чтобы поощрять освещение только то, что необходимо, когда это необходимо. Имея 58 отделений в шестнадцати странах, МАР стала движущей силой создания девяти мировых заповедников, в том числе последнего биосферного заповедника Рон площадью 1720 квадратных километров в Германии. Кампании IDA также снизили уличное освещение в нескольких штатах США и изменили национальное законодательство в Италии. Ф За исключением некоторых парков и зон обсерваторий, IDA не защищает полную темноту, признавая, что городские районы работают круглосуточно. Для транспорта особенно важно освещение. Тем не менее, существует заметная разница между резкими яркими огнями и теми, которые освещают землю, но не устремляются в небо. Министерство транспорта США недавно провело исследование безопасности шоссе и обнаружило, что шоссе, хорошо освещенное только на развязках, так же безопасно, как и шоссе, освещенное по всей длине.Кроме того, светоотражающие вывески и стратегическая белая краска улучшили безопасность больше, чем добавление света. Исследование Министерства юстиции США показало, что наружное освещение не может сдерживать преступность. Единственная реальная выгода - в восприятии граждан: освещение снижает страх перед преступностью, а не самой преступностью. В самом деле, яркий свет может поставить под угрозу безопасность, поскольку делает жертв и имущество более заметными. IDA рекомендует, чтобы уличные фонари оставались включенными всю ночь, они имели меньшую яркость или регулировались диммерами; и что они направлены вниз или оснащены направленными металлическими экранами.В частных домах ночники с малым светом должны включаться только при обнаружении движения. г Это не просто светлячок, летучая мышь или туман, который страдает от светового загрязнения - многие люди больше не испытывают наполнения звезд или каких-либо других звезд, кроме самых ярких, и, следовательно, не задумываются о своем собственном месте во Вселенной. Надеемся, что отмеченные призами светодиодные фонари будут модифицированы и использованы с осторожностью, чтобы вернуть нам все великолепие ночного неба. Вопросы 28-32 Читальный пассаж 3 состоит из семи секций, A-G . В каком разделе содержится следующая информация? Напишите правильную букву A-G в ячейках 28-32 на листе для ответов. 28 Беззаботный пример незнания ночного неба 29 Объяснение того, что освещение может не соответствовать безопасности 30 Описание деятельности Международной ассоциации темного неба 31 Пример детенышей животных, на которых слишком много ночного света 32 Список возможных недостатков новой светотехники Вопросы 33-35 Закончите предложения ниже. Выберите ОДНО СЛОВО ИЛИ НОМЕР из отрывка для каждого ответа. Запишите свои ответы в графу 33-35 на листе для ответов. 33 Слишком много ……………… .. света привело к увеличению числа серьезных заболеваний. 34 Примерно ……………… ..% людей не могут видеть Млечный Путь. 35 Ежегодно около ……………… миллионов перелетных птиц умирают, врезавшись в освещенные высокие здания. Вопросы 36-39 Соответствуют ли следующие утверждения утверждениям автора в отрывке 3? В ячейках 36-39 на листе для ответов напишите: ДА если заявление согласуется с утверждениями автора НЕТ , если заявление противоречит утверждениям автора. НЕ ДАЕТ , если невозможно сказать, что думает по этому поводу писатель. 36 Вызывает тревогу то, что так много животных погибает от ночного освещения. 37 Хорошо, что в развивающихся странах теперь более яркое освещение. 38 Итальянцам не нужно беспокоиться об уменьшении уличного освещения. 39 Яркие огни вдоль дороги необходимы для безопасного вождения. Вопрос 40 Выберите правильную букву A , B , C или D . Напишите правильное письмо в графе 40 на листе для ответов. По словам писателя, сколько должно быть ночного освещения по сравнению с тем, что есть? A Намного больше B Немного больше C Немного меньше D Намного меньше . |
|